Mô hình Arima với phương pháp Box - Jenkins và ứng dụng để dự báo lạm phát của Việt Nam
Ông Nguyên Chương
Trường Đại học Kinh tế, Đại học Đà Nẵng
Tóm tắt
Sự tác động của lạm phát có cả tích cực và tiêu cực theo những cách thức khác nhau tùy thuộc vào cấu trúc của nền kinh tế, khả năng thích ứng với sự thay đổi liên tục của lạm phát và mức độ tiên liệu một cách toàn diện về lạm phát. Vì vậy, dự báo lạm phát không chỉ có ý nghĩa trong việc cung cấp các thông tin cho những nhà hoạch định chính sách mà còn đối với cả các nhà kinh doanh trong việc điều chỉnh các chiến lược; Và tính ổn định kinh tế vĩ mô có liên quan đến mức độ tương đồng hay khác biệt giữa các dự báo về lạm phát của các nhà kinh doanh và của các nhà hoạch định chính sách. Mô hình ARIMA với phương pháp Box-Jenkins được ứng dụng để dự báo lạm phát hàng tháng của Việt Nam với dữ liệu từ Tổng cục Thống kê.
1. Giới thiệuNhiều nghiên cứu, đặc biệt là các nghiên cứu thực nghiệm cho thấy sự tác động của lạm phát có cả tích cực và tiêu cực theo những cách thức khác nhau tùy thuộc vào cấu trúc của nền kinh tế, khả năng thích ứng với sự thay đổi liên tục của lạm phát và mức độ tiên liệu một cách toàn diện về lạm phát. Lạm phát cao có xu hướng làm thay đổi các cân bằng thực của nền kinh tế làm chệch hướng các nguồn lực khi thực hiện các giao dịch; giảm tín hiệu thông tin về giá tương đối vì vậy dẫn đến tình trạng phân bổ nguồn lực không hiệu quả. Khi lạm phát tăng làm giá trị của tiền giảm khiến chức năng là đơn vị hạch toán của tiền thay đổi, điều này làm cho việc hạch toán chi phí-lợi nhuận của doanh nghiệp trở nên khó khăn; tác hại của lạm phát không dự kiến được gia tăng sự bất ổn định, dẫn đến tình trạng tái phân phối của cải một cách tùy tiện (chẳng hạn, khi lạm phát cao hơn so với dự kiến người đi vay được lợi và người cho vay bị thiệt).
Vì vậy, dự báo lạm phát không chỉ có ý nghĩa trong việc cung cấp các thông tin đối với những nhà hoạch định chính sách kinh tế vĩ mô mà còn đối với cả các nhà kinh doanh trong việc điều chỉnh các chiến lược kinh doanh.
Có nhiều phương pháp tiếp cận trong phân tích và dự báo lạm phát. Mục đích của bài viết này nhằm ứng dụng mô hình ARIMA với phương pháp Box-Jenkins để dự báo lạm phát ở Việt Nam.
George Box và Gwilym Jenkins (1976) đã nghiên cứu mô hình ARIMA (Autoregressive Integrated Moving Average - Tự hồi qui tích hợp Trung bình trượt), và tên của họ thường được dùng để gọi tên các quá trình ARIMA tổng quát, áp dụng vào việc phân tích và dự báo các chuỗi thời gian. Phương pháp Box-Jenkins với bốn bước lặp: nhận dạng mô hình thử nghiệm; ước lượng; kiểm định bằng chẩn đoán; và dự báo.
2. Dự báo lạm phát của Việt Nam
2.1. Nhận dạng mô hình
Trong thực tế, chúng ta phải đối mặt với hai câu hỏi quan trọng: (1) Bằng cách nào chúng ta xác định được một chuỗi thời gian là dừng; (2) Nếu chúng ta xác định được một chuỗi thời gian không dừng, thì có cách nào để có thể làm cho chúng trở nên dừng.
Mặc dù có nhiều cách để kiểm tra tính dừng, nhưng có hai cách được sử dụng phổ biến nhất là đồ thị (phân tích đồ thị và kiểm định bằng đồ thị tương quan (correlogram) và kiểm định nghiệm đơn vị (unit root test)[1] (Gujarati, 2003).
Toán tử dịch chuyển lùi và sai phân (Back-shift Operator and Differences)
Điều trước tiên cần phải lưu ý là hầu hết các chuỗi thời gian đều không dừng, và các thành phần AR và MA của mô hình ARIMA chỉ liên quan đến các chuỗi thời gian dừng. Cho nên, cần phải có một ký hiệu phân biệt những chuỗi thời gian không dừng gốc với những chuỗi tương ứng có tính dừng của nó sau khi biến đổi sai phân.
Một ký hiệu rất hữu ích là toán tử dịch chuyển lùi (trễ), L, được dùng như sau:
LYt=Yt – 1; nói cách khác, L, thực hiện trên Yt, có tác dụng dịch chuyển dữ liệu trở lại một thời đoạn.
Áp dụng L trên Yt hai lần sẽ dịch chuyển dữ liệu trở lại 2 thời đoạn: L(LYt)=L2Yt=Yt - 2
Đối với dữ liệu tháng, nếu dịch chuyển đến “cùng tháng trong năm trước”, thì dùng L12, và ký hiệu là L12Yt = Yt-12.
Toán tử dịch chuyển lùi thuận tiện trong việc mô tả quá trình tính sai phân.
Sai phân bậc nhất: DYt = Yt - Yt - 1
Sử dụng toán tử dịch chuyển lùi, có thể viết lại như sau.
DYt = Yt - LYt = (1 - L)Yt
Lưu ý rằng sai phân bậc nhất được biểu diễn bởi (1 - L). Tương tự, nếu tính sai phân bậc hai (nghĩa là, sai phân bậc nhất của sai phân bậc nhất), thì:
Sai phân bậc hai
D2Yt = DYt - DYt -1 = (1 - 2L + L2) Yt = (1 - L)2Yt
Lưu ý sai phân bậc hai được ký hiệu là (1 - L)2. (Điều quan trọng là phải nhận thấy được sai phân bậc hai không phải là sai phân thứ hai, được ký hiệu là 1 - L2. Tương tự, sai phân thứ mười hai sẽ là 1 - L12, nhưng sai phân bậc mười hai sẽ là (1 - L)12)
Mục đích của việc lấy sai phân là để đạt được trạng thái dừng, và tổng quát nếu lấy sai phân bậc thứ d sẽ đạt được dừng,
DdYt = (1 - L)dYt là chuỗi dừng,
Phương pháp Box-Jenkins dựa vào:
1. Phân tích đồ thị
Vẽ đồ thị dữ liệu chuỗi thời gian, thông qua hình dạng của đồ thị thực nghiệm cung cấp những gợi ý ban đầu về bản chất của chuỗi thời gian. Đồ thị cung cấp hình ảnh trực quan cho phép chúng ta có thể đánh giá một chuỗi thời gian có dừng hay không.
2. Kiểm định bằng đồ thị tương quan thông qua hàm tự tương quan và hàm tự tương quan từng phần.
Hàm tự tương quan mẫu(Sample Autocorrelation Function-SACF)
Hàm tự tương quan tại độ trễ k (hay bậc trễ k) ký hiệu rk là:

Bên cạnh hệ số tương quan rk, sai số chuẩn của rk gọi là srk và trị thống kê trk sẽ được sử dụng để giúp chúng ta nhận dạng thử nghiệm một mô hình Box-Jenkins.
Sai số chuẩn của rk là

Hàm tự tương quan của mẫu (SACF) là một hàm hay đồ thị của độ tự tương quan của mẫu ở độ trễ k = 1, 2, . . .
SACF có thể được dùng để giúp chúng ta tìm ra một chuỗi thời gian dừng zb, zb+1,…,zn. Việc này có thể được thực hiện vì chúng ta có thể liên kết động thái của SACF với sự dừng của chuỗi thời gian. Tổng quát, với một chuỗi số liệu không có tính mùa có thể chỉ ra rằng:
1. Nếu SACF của chuỗi thời gian zb, zb+1,…, znhoặc giảm thật nhanh hoặc giảm dần khá nhanh thì giá trị của chuỗi thời gian được xem là dừng.
2. Nếu SACF của chuỗi thời gian zb, zb+1 ,…, zngiảm dần thật chậm thì chuỗi thời gian được xem là không dừng.
Ý nghĩa chính xác của từ “khá nhanh” và “thật chậm” có phần tùy ý và tốt nhất được xác định bằng kinh nghiệm. Hơn thế nữa, kinh nghiệm chỉ ra rằng với dữ liệu không với tính mùa, việc SACF giảm khá nhanh, nếu có, thường xảy ra sau một độ trễ k bé hơn hay bằng 2.
Hàm tự tương quan từng phần của mẫu (Sample Partial Autocorrelation Function-SPACF)
Chúng ta sẽ định nghĩa hàm tự tương quan từng phần của mẫu (SPACF).
1. Giá trị tương quan từng phần của mẫu tại độ trễ k là:
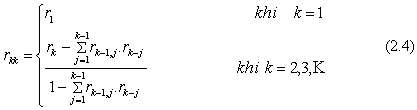
Ở đây: rkj= rk-1,j - rkk .rk-1,k-jvới j=1, 2, …, k-1
2. Sai số chuẩn của rkklà
srkk =1/(n-b+1)1/2 (2.5)
3. Trị thống kê trkklà
là trkk = rkk/ srkk (2.6)
4. Hàm tự tương quan từng phần của mẫu (SPACF) là một danh sách hay đồ thị của các trị số tự tương quan từng phần của mẫu ở các độ trễ k=1,2,…
Đại lượng này mô tả một cách trực giác các trị tự tương quan của mẫu đối với các giá trị quan sát chuỗi thời gian ngăn cách bằng một độ trễ k lần đơn vị thời gian
Một lần nữa, để áp dụng phương pháp luận Box-Jenkins, chúng ta phải thử và cố gắng phân loại động thái của SPACF. Đầu tiên, SPACF của một chuỗi thời gian không có tính mùa có thể giảm thật nhanh. Điều này có ý nghĩa gì, ta nói rằng một đỉnh nhọn ở độ trễ k tồn tại trong SPACF nếu rkk, trị tự tương quan từng phần của mẫu ở độ trễ k, là lớn theo nghĩa thống kê. Kết luận rằng rkk là lớn theo nghĩa thống kê một cách cơ bản tương đương với việc loại bỏ giả thuyết không cho rằng trị tự tương quan từng phần lý thuyết ở độ trễ k, ký hiệu Pkk, bằng không. (H0 : Pkk = 0). Ta có thể đánh giá một đỉnh nhọn ở độ trễ k tồn tại trong SPACF hay không bằng cách xem trị thống kê t tương ứng với rkk. Ở đây ta xem một đỉnh nhọn ở độ trễ k tồn tại trong SPACF nếu trị tuyệt đối của ![]() là lớn hơn 2. Hơn thế nữa, chúng ta nói rằng SPACF giảm thật nhanh sau độ trễ k nếu không có đỉnh nhọn nào ở các độ trễ lớn hơn k trong SPACF . Với dữ liệu không có tính mùa, kinh nghiệm chỉ ra rằng nếu SPACF tắt, một cách tổng quát nó sẽ giảm thật nhanh sau một độ trễ bé hơn hay bằng 2. Thứ hai, chúng ta nói rằng SPACF giảm dần nếu hàm này không giảm thật nhanh nhưng giảm đi theo một “dạng ổn định”. SPACF có thể giảm dần theo (1) một dạng hàm mũ tắt dần (không dao động hoặc có dao động), (2) một dạng sóng hình sin tắt dần hoặc (3) một dạng bị trội bởi một trong hai dạng trên hoặc một tổ hợp của chúng. Hơn nữa, SPACF có thể giảm dần khá nhanh hoặc giảm dần thật chậm.
là lớn hơn 2. Hơn thế nữa, chúng ta nói rằng SPACF giảm thật nhanh sau độ trễ k nếu không có đỉnh nhọn nào ở các độ trễ lớn hơn k trong SPACF . Với dữ liệu không có tính mùa, kinh nghiệm chỉ ra rằng nếu SPACF tắt, một cách tổng quát nó sẽ giảm thật nhanh sau một độ trễ bé hơn hay bằng 2. Thứ hai, chúng ta nói rằng SPACF giảm dần nếu hàm này không giảm thật nhanh nhưng giảm đi theo một “dạng ổn định”. SPACF có thể giảm dần theo (1) một dạng hàm mũ tắt dần (không dao động hoặc có dao động), (2) một dạng sóng hình sin tắt dần hoặc (3) một dạng bị trội bởi một trong hai dạng trên hoặc một tổ hợp của chúng. Hơn nữa, SPACF có thể giảm dần khá nhanh hoặc giảm dần thật chậm.
Quá trình nhận dạng của một mô hình ARIMA không có tính mùa hay có tính mùa phụ thuộc vào những công cụ thống kê - đó là, hệ số tự tương quan, hệ số riêng phần, và đồ thị tương quan; và hiểu biết về quá trình đang nghiên cứu cũng như đòi hỏi kinh nghiệm và phán đoán tốt (Newbold and Bos, 1994).
Mô hình ARIMA mở rộng bao gồm các yếu tố thời vụ được ký hiệu tổng quát là:
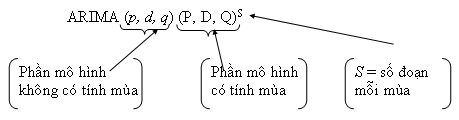
Dữ liệu được sử dụng là Chỉ số giá tiêu dùng (CPI) hàng tháng theo phương pháp liên hoàn từ tháng 1 năm 1996 đến tháng 12 năm 2006 của Tổng Cục Thống kê công bố.
Tỷ lệ lạm phát hàng tháng sẽ được xác định[2]:
![]()
Trong đó :
![]() : tỷ lệ lạm phát thời điểm t (biểu thị bằng %)
: tỷ lệ lạm phát thời điểm t (biểu thị bằng %)
CPLt : Chỉ số giá tiêu dùng thời điểm t
CPLt-1 : Chỉ số giá tiêu dùng thời điểm t-1
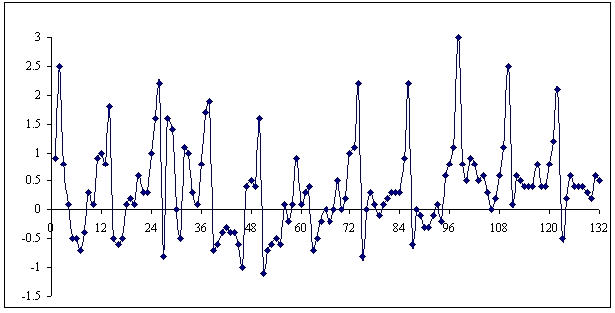
Hình 2.1. Tỷ lệ lạm phát hàng tháng (%)
Hình 2.2. Đồ thị tương quan của dữ liệu sau khi biến đổi sai phân
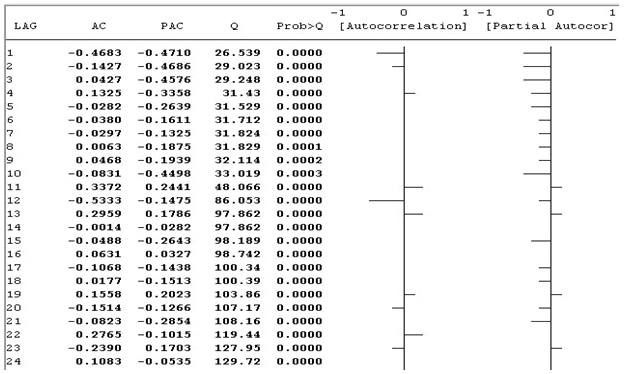
Dựa vào hình dạng của đồ thị thực nghiệm của dữ liệu gốc (Hình 2.1) và đồ thị tương quan của dữ liệu sau khi biến đổi sai phân (Hình 2.2).
Các mô hình được nhận dạng như sau:
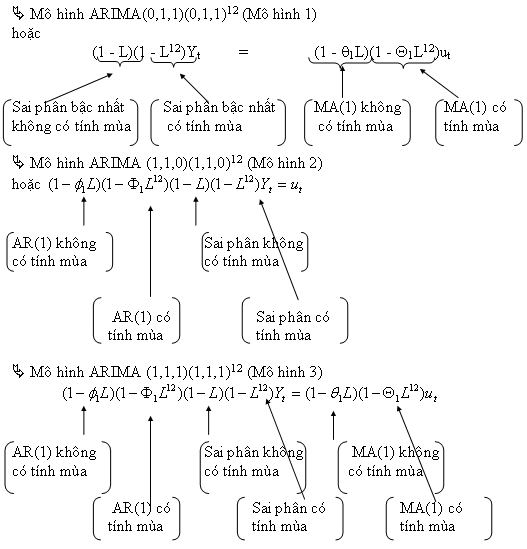
2.2. Ước lượng các tham số
Cơ bản có hai cách để ước lượng những tham số ![]()
1. Thử và sai – Xem xét nhiều giá trị khác nhau và chọn giá trị (hay tập giá trị, nếu ước lượng nhiều hơn một tham số) sao cho tổng của những bình phương phần dư đạt giá trị nhỏ nhất.
2. Cải thiện lặp - chọn một ước lượng ban đầu và chạy bằng một chương trình máy tính tinh chỉnh ước lượng lặp đi lặp lại[1].
Bảng 2.1. Kết quả các tham số của các mô hình được ước lượng[2]
| Mô hình 1 | Mô hình 2 | Mô hình 3 | ||||||
| DS12.inf | Coef. | z | DS12.inf | Coef. | z | DS12.inf | Coef. | z |
| inf | inf | inf | ||||||
| _cons | 0.001 | 0.15 | _cons | -0.002 | -0.05 | _cons | 0.001 | 0.36 |
| ARMA | ARMA | ARMA | ||||||
| Ma | ar | ar | ||||||
| L1. | -0.616 | -10.36 | L1. | -0.166 | -1.63 | L1. | 0.448 | 4.4 |
| ARMA12 | ARMA12 | ma | ||||||
| Ma | ar | L1. | -0.909 | -11.11 | ||||
| L1. | -1.000 | L1. | -0.458 | -6.53 | ARMA12 | |||
| ar | ||||||||
| L1. | -0.088 | -0.86 | ||||||
| ma | ||||||||
| L1. | -1.000 | |||||||
2.3. Kiểm định mô hình
Sau khi ước lượng các tham số của một mô hình ARIMA được nhận dạng thử, chúng ta cần phải kiểm định để kiểm nghiệm rằng mô hình là thích hợp. Có hai cách thức cơ bản để thực hiện điều này:
1. Xem xét những phần dư - để xem nó theo dạng nào chưa được biết không.
2. Xem xét những thống kê lấy mẫu của giải pháp tối ưu hiện tại (sai số chuẩn, ma trận tương quan...)-kiểm tra xem có thể đơn giản hoá mô hình không.
Bảng 2.2. Kết quả các thông số kiểm định
| Model | Obs | Chi-Square | ll(model) | df | AIC | BIC |
| Mô hình 1 | 119 | 109.42 | -85.63 | 4 | 169.26 | 180.38 |
| Mô hình 2 | 119 | 45.94 | -109.78 | 4 | 227.55 | 238.67 |
| Mô hình 3 | 119 | 115.46 | -79.28 | 5 | 168.57 | 182.46 |
Dựa vào Bảng 2.1 và Bảng 2.2 với các tiêu chuẩn kiểm định được lựa chọn là z, Chi-Square ( X2 ), AIC (Akaike Information Criterion) và BIC (Bayesian Information Criterion), mô hình phù hợp nhất và được lựa chọn là Mô hình 1.
2.4. Dự báo bằng mô hình ARIMA
Mô hình ARIMA (0,1,1)(0,1,1)12
![]() (2.8)
(2.8)
Tuy nhiên, để sử dụng một mô hình được nhận dạng cho dự báo, cần phải mở rộng mô hình (2.8) trở thành:
![]() (2.9)
(2.9)
Khi sử dụng phương trình này để dự báo một thời đoạn tiếp theo - nghĩa là, Yt+1 - chúng ta tăng những chỉ số lên một, từ đầu đến cuối, như trong phương trình (2.9).
![]() (2.10)
(2.10)
Số hạng ut+1 sẽ không biết được vì giá trị kỳ vọng của những sai số ngẫu nhiên tương lai bằng 0, nhưng từ mô hình đã thích hợp, chúng ta có thể thay thế những giá trị ut, ut-11, và ut-12 bằng những giá trị được xác định bằng thực nghiệm của chúng - nghĩa là, như những giá trị thu được sau lần lặp sau cùng của giải thuật Marquardt. Dĩ nhiên, vì chúng ta dự báo xa hơn nữa trong tương lai, chúng ta sẽ không có những giá trị thực nghiệm cho những số hạng “u” sau một khoảng nào đó, và vì vậy tất cả những giá trị kỳ vọng của chúng sẽ có giá trị là không.
Đối với những giá trị Y ban đầu của quá trình dự báo, chúng ta sẽ biết những giá trị Yt, Yt-11, và Yt-12. Tuy nhiên, sau một lúc, những giá trị Y trong phương trình (2.10) sẽ là những giá trị được dự báo chứ không phải là những giá trị quá khứ. Vì vậy các giá trị thực tế cần phải được cập nhật liên tục để cải thiện độ tin cậy của các giá trị dự báo.
Bảng 2.3. Kết quả dự báo lạm phát hàng tháng từ tháng 1 đến tháng 12 năm 2007
| Tháng 1 | Tháng 2 | Tháng 3 | Tháng 4 | Tháng 5 | Tháng 6 | Tháng 7 | Tháng 8 | Tháng 9 | Tháng 10 | Tháng 11 | Tháng 12 |
| 0.79 | 1.46 | -1.06 | -0.10 | 0.60 | 0.44 | 0.20 | 0.31 | 0.34 | 0.48 | 0.89 | 0.76 |
TÀI LIỆU THAM KHẢO
- Tổng cục Thống kê, Chỉ số giá tiêu dùng các tháng trong năm, 2007.
- Box, G.E.P., and G.M. Jenkins, Time Series Analysis: Forecasting and Control, Revised Edition, Holden Day, San Francisco, 1976.
- Gujarati, D., Basic Econometrics, 4th ed., McGraw Hill, New York, 2003.
- Newbold, P. and Bos, T., Introductory business and economic forecasting (2nd edition), International Thomson Publishing, 1994.
[1]Kiểm định được sử dụng phổ biến là kiểm định Dickey-Fuller tăng cường (Augmented Dickey-Fuller-ADF).
[3]Phương pháp Cải thiện lặp được ứng dụng rộng rãi hơn vì giải thuật mạnh.(giải thuật Marquardt)
[4] Sử dụng phần mềm Stata
[2]Có nhiều cách để xác định tỷ lệ lạm phát dựa vào các phương pháp tính chỉ số giá khác nhau như Chỉ số giá sản xuất (PPI), Chỉ số điều chỉnh GDP (GDP deflator), Chỉ số giá “dây chuyền” (chained price index; hoặc tỷ lệ lạm phát cơ bản (core inflation)-loại trừ những loại hàng hoá và dịch vụ mà giá cả của chúng biến động theo thời vụ hoặc thất thường.
(Ông Nguyên Chương -Trường Đại học Kinh tế, Đại học Đà Nẵng// Internet)
Bài thuộc chuyên đề: Tỷ lệ lạm phát ở Việt Nam ?
[
Trở về]
- Quá lớn để sụp đổ hay quá lớn để tồn tại?
- Tìm kiếm trường đại học và nghề nghiệp cho con bạn
- Tố chất lãnh đạo do bẩm sinh hay được tôi luyện?
- Phải chăng Thế hệ Y quá đề cao bản thân mình?
- Trung Quốc trở thành lò sản xuất nữ tỉ phủ thế nào?
- Chiến lược hình thành cơ cấu và câu chuyện Dubai
- Cần tạo thị trường cạnh tranh hơn
- Đầu tư môi trường tạo lợi thế kinh doanh
 |
 |
 |
 |
- Về tay người Thái, dấu chấm hết cho hàng Việt ở Metro?
- Núi tiền khổng lồ của chúa đảo Tuần Châu
- Từ 'Share a Coke' đến tư duy truyền thông thời công nghệ số
- Nhà họ Lee mất dần quyền kiểm soát Samsung
- Tạp chí Forbes về tay nhóm nhà đầu tư Hồng Kông
- Anh em Bầu Thụy hết nổ và chán nổi
- Suy nghĩ về tiền theo tư duy của triệu phú
- CEO cao giá chưa chắc làm việc hiệu quả
- 10 công ty lãi lớn nhất thế giới
- 9 dự án “ngoài sức tưởng tượng” của Google
Chuyển nhượng, cho thuê hoặc hợp tác phát triển nội dung trên các tên miền:
Hoa Đà Lạt
Giá vàng SJC
Thị trường vàng
Mua sắm - Tư vấn mua sắm
Nội thất gỗ
Nhà xuất khẩu Việt Nam
Món ngon Việt
Tư vấn nhà đẹp
Hỏi luật gia - Hội luật gia
Kho hàng trực tuyến
Việc làm online
Cho người Việt Nam
Sắc màu Việt
Quý vị quan tâm xin liên hệ: tieulong@6vnn.com





